Generatywna sztuczna inteligencja wkracza do każdego zakątka świata IT, ale dotychczas lokalne testowanie i uruchamianie modeli bywało kłopotliwe. Rozproszenie narzędzi, problemy z kompatybilnością sprzętową czy rozdzielenie środowiska kontenerów od workflow aplikacyjnego wydłużały czas iteracji. Teraz z pomocą przychodzi nam Docker Model Runner – nowy sposób na szybkie, proste i w pełni zintegrowane uruchamianie modeli AI w Docker.
Czytaj dalej Docker Model Runner – nowy sposób na lokalne uruchamianie modeli LLMTag: Apple
Mac Studio M3 Ultra z 512GB RAM!
Od kilku tygodni można już zamawiać nowego Mac Studio z procesorem M3 Ultra, jest to co prawda poprzednia generacja procesora Apple Silicon, ale Mac Studio z M3 Ultra daje nam coś czego nie dostaniemy w Mac Studio z M4 Max, chodzi o ilość RAMu. W przypadku M3 Ultra możemy mieć aż 512GB zunifikowanej pamięci RAM! To oznacza, że możemy uruchomić lokalnie naprawdę duże modele LLM, np. DeepSeek R1.
Oprócz rozmiaru pamięci kluczowa jest też przepustowość pamięci:
- 410GB/s – Mac Studio z M4 Max (14 core),
- 546GB/s – Mac Studio z M4 Max (16 core),
- 819GB/s – Mac Studio z M3 Ultra.
Ponad 800GB/s to jest naprawdę dobry wynik. To co, zamawiamy?
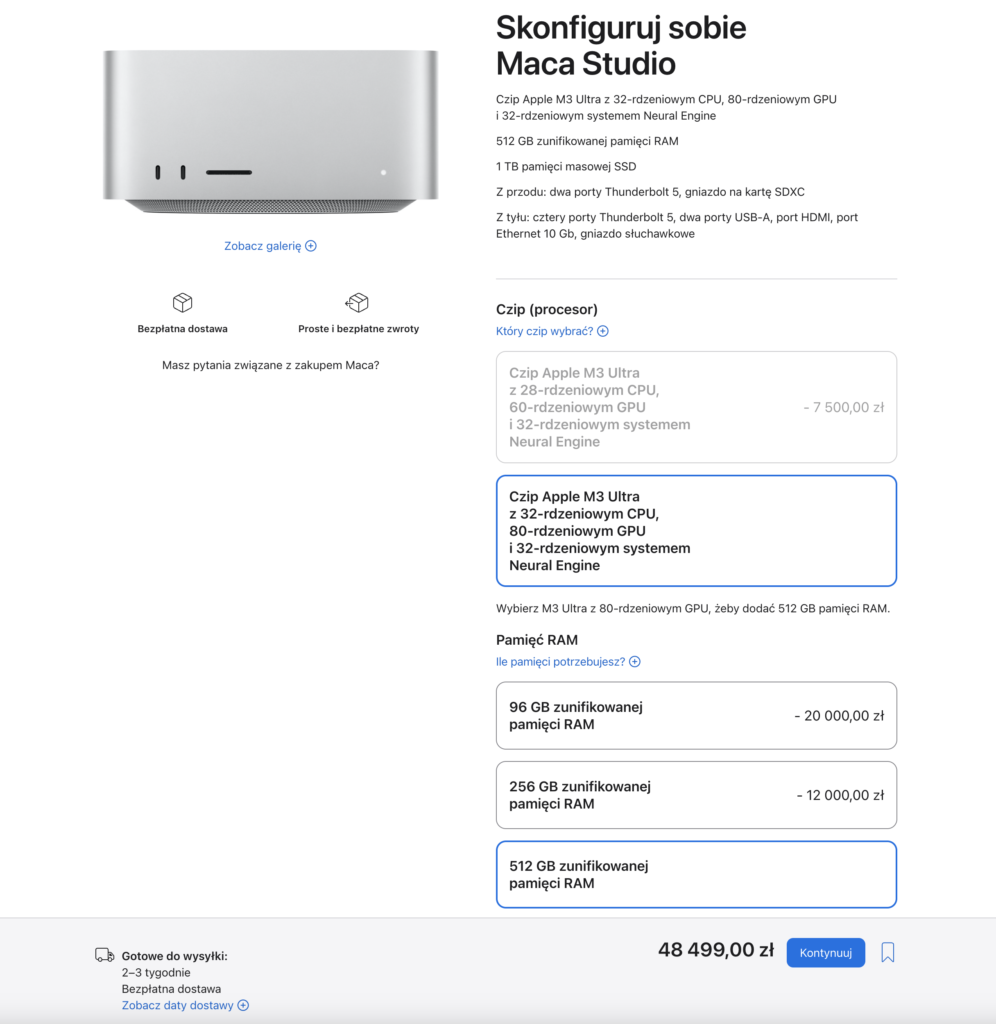
Apple wypuściło sprzęt, który z powodzeniem może być wykorzystywany jako lokalny system dla modeli AI, zwłaszcza gdy nie chcemy wysyłać naszych danych do chmury i tracić nad nimi kontroli.